Here is one of our exciting just-finished ACL papers. David and I designed an algorithm that learns different types of character personas — “Protagonist”, “Love Interest”, etc — that are used in movies.
To do this we collected a brand new dataset: 42,306 plot summaries of movies from Wikipedia, along with metadata like box office revenue and genre. We ran these through parsing and coreference analysis to also create a dataset of movie characters, linked with Freebase records of the actors who portray them. Did you see that NYT article on quantitative analysis of film scripts? This dataset could answer all sorts of things they assert in that article — for example, do movies with bowling scenes really make less money? We have released the data here.
Our focus, though, is on narrative analysis. We investigate character personas: familiar character types that are repeated over and over in stories, like “Hero” or “Villian”; maybe grand mythical archetypes like “Trickster” or “Wise Old Man”; or much more specific ones, like “Sassy Best Friend” or “Obstructionist Bureaucrat” or “Guy in Red Shirt Who Always Gets Killed”. They are defined in part by what they do and who they are — which we can glean from their actions and descriptions in plot summaries.
Our model clusters movie characters, learning posteriors like this:
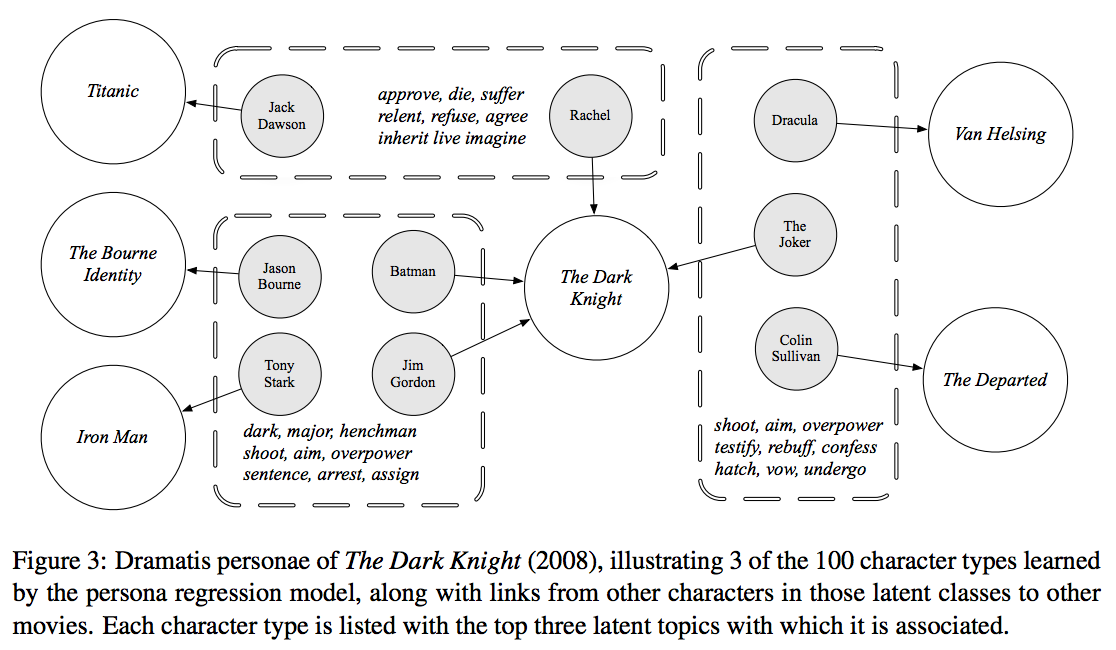
Each box is one automatically learned persona cluster, along with actions and attribute words that pertain to it. For example, characters like Dracula and The Joker are always “hatching” things (hatching plans, presumably).
One of our models takes the metadata features, like movie genre and gender and age of an actor, and associates them with different personas. For example, we learn the types of characters in romantic comedies versus action movies. Here are a few examples of my favorite learned personas:

One of the best things I learned about during this project was the website TVTropes (which we use to compare our model against).
We’ll be at ACL this summer to present the paper. We’ve posted it online too:
- Learning Latent Personae of Film Characters.
David Bamman, Brendan O’Connor, and Noah A. Smith.
ACL 2013, Sofia, Bulgaria, August 2013
Dataset
Pingback: LightSide | LightSide’s Top Ten Papers at ACL 2013
Pingback: LightSide’s Top Ten Papers at ACL 2013 | LiXiang