Here’s a great project from Andy Baio and Joshua Schachter: they assessed the political biases of different blogs based on which articles they tend link to. Using these political bias scores, they made a cool little Firefox extension that colors the names of different sources on the news aggregator site Memeorandum, like so:
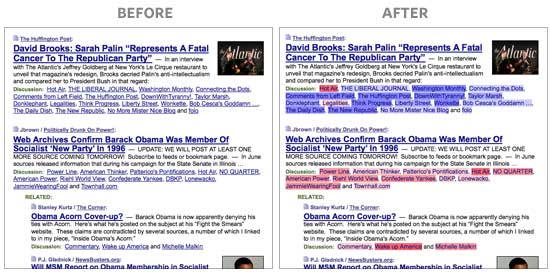
How they computed these biases is pretty neat. Their data source was the Memeorandum site itself, which shows a particular news story, then a list of different news sites that have written articles about the topic. Scraping out that data, Joshua constructed the adjacency matrix of sites vs. articles they linked to and ran good ol’ SVD on it, an algorithm that can be used to summarize the very high-dimensional article linking information in just several numbers (“components” or “dimensions”) for each news site. Basically, the algorithm groups together sites that tend to link to the same articles. It’s not exactly clustering though; rather, it projects them into a space where sites close to each other had similar linking patterns. People have used this technique analogously to construct a political spectrum for Congress, by analyzing which legislators tend to vote together.
So here they found that the second dimension of the SVD’s projected outputs seemed to strongly correlate with their own intuitions of sites’ political biases. Talk about getting lucky! This score is used for their coloring visualization, and I personally found the examples pretty accurate. And they helpfully posted all of their output data with the blog post.
There is a concern though. The funny thing about SVD (and related algorithms like factor analysis and PCA) is that the numbers that fall out of it don’t necessarily mean anything. In fact there have been great controversies when researchers try to interpret its outputs. For example, if you run PCA on scores from different types of IQ tests, you get a “g factor”. Is it a measure of general human intelligence? Or is g just a meaningless statistical artifact? No one’s sure.
But for this problem, there is a fair, objective validation — use 3rd party, human judgments from the web! I’ve found before that you can assess media bias on AMT pretty well; but for this, I simply went to a pre-existing site called Skewz, which collects people’s ratings of the bias of individual articles from news sites. About 150 sites were rated on Skewz as well as included in the Memeorandum/SVD analysis.
Within that set, it turns out that the SVD’s second component significantly correlates with Skewz users’ judgments of political bias! First, here’s the scatterplot of the “v2″ SVD dimension against Skewz ratings. Higher numbers are conservative, lower are liberal:

So SVD tends to give most sites a neutral score, but when it assigns a strong score, it’s often right — or at least, correlates with Skewz users. Some of the disagreements are interesting — for example, Skewz thinks The New Republic is liberal, whereas SVD thinks it’s slightly conservative. That might mean that TNR links to lots of stories that conservatives tend to like, though its actual content and stances are liberal. (But don’t take any particular data point too seriously — the Skewz data is probably fairly noisy, and the bridging between the datasets introduces more noise too, since Memeorandum and Skewz are based on different sets of articles and such.)
Here’s a zoom-in on that narrow band in the middle. There’s some more successful correlation in there:

Here are the actual correlation coefficients with the different SVD outputs. It turns out the first dimension slightly correlates to political bias as well. (Joshua explained it as the overall volume of linking. Do liberals tend to link more?) But the third through fifth dimensions, which they say were very hard for them to interpret, don’t correlate at all to these political bias ratings.
| SVD component (output dimension)
| v1
| v2
| v3
| v4
| v5
|
| Correlation to Skewz ratings
| +.112
| +.392
| -.011
| -.057
| -.047
|
In conclusion … this overall result makes me really happy. A completely unsupervised algorithm, based purely on similarity of linking patterns, gets you a systematic correlation with independent judges’ assessments of bias. That’s just sweet.
Here’s the entire dataset for the above graphs. “score_svd” is their rescaled version of “v2″. (Click here to see and download all of it).
Update: See the comments below. You can also fit a linear model against all of v1..v5 to predict the Skewz rating as the response. This fits a little better than using just v2. Here’s the scatterplot for the model’s predictions.

Code: I put the Skewz scraper, data, and scripts up here.
Final note: The correlation coefficients above are via Kendall-Tau, which is invariant to rescalings of the data. This data has all sorts of odd spikes and such, and Joshua and Andy themselves rescaled the data for the coloring plugin, so this seemed safest. And don’t worry about the small sample size; v1 correlation’s p-value is .04, v2 correlation p-value is tiny.







