There’s a lot to say about Powerset, the short-lived natural language search company (2005-2008) where I worked after college. AI overhype, flying too close to the sun, the psychology of tech journalism and venture capitalism, etc. A year or two ago I wrote the following bit about Powerset’s technology in response to a question on Quora. I’m posting a revised version here.
Question: What was Powerset’s core innovation in search? As far as I can tell, they licensed an NLP engine. They did not have a question answering system or any system for information extraction. How was Powerset’s search engine different than Google’s?
My answer: Powerset built a system vaguely like a question-answering system on top of Xerox PARC’s NLP engine. The output is better described as query-focused summarization rather than question answering; primarily, it matched semantic fragments of the user query against indexed semantic relations, with lots of keyword/ngram-matching fallback for when that didn’t work, and tried to highlight matching answers in the result snippets.
The Powerset system indexed semantic relations and entities (the latter often being wordnet/freebase nodes), did a similar analysis on the user query, then formed a database query against that index of semantic relations, synonym/hypernym expansions, and other textual information (e.g. word positions or gender identification). Then with all the rich (complicated) index information, you have neat features for ranking and snippet generation (i.e. query-focused summarization), but it’s so complicated it’s easy to screw up. (And don’t get me started on trying to run a segfault-prone Tcl/Prolog/C parser under an unstable 2006-era Hadoop…)
Here is a diagram I wrote in July 2007 to try to communicate internally what the entire system was doing. As you might imagine, it was difficult to keep everyone on the same page. This diagram only depicts the indexing pipeline; the query-time system would have required another diagram. NLP folks will note some rather surprising technology choices in some places. (Unweighted FST for NER? Yes. In fairness, it was eventually replaced by a statistical tagger. But the company did have >$12 million in funding at this point.)
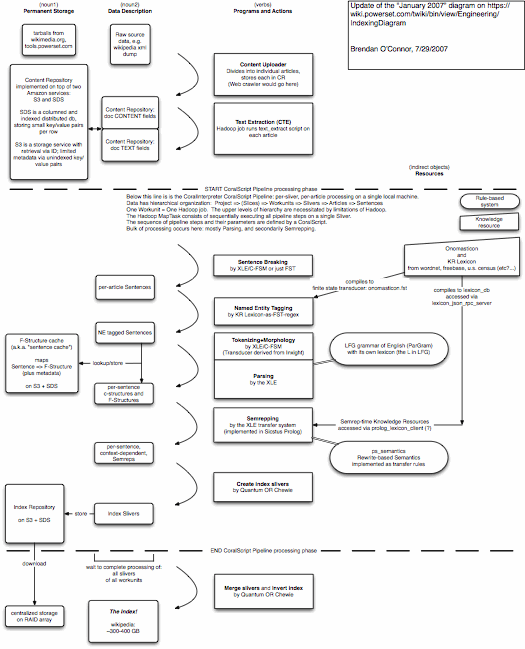
As to whether this was “different than Google,” sure, I suppose. Certainly no serious search engine was crazy enough to do constituent parses (and unification parses, lexical lookups, coreference, etc.) of all sentences at index time — raising indexing costs, compared to keyword indexing, by perhaps 100x — but Powerset sure did.
It’s worth noting that since then, Google has added much more question-answering and structured information search, presumably using related but different techniques than Powerset used. (And Google even had some simple question-answering back then, as I recall; and, these days it’s said they parse the web all the time, at least for experimental purposes. They now have excellent groups of highly-regarded specialists in parsing, unsupervised lexical semantics, machine translation, etc., which Powerset never did.) And IBM’s Watson project more recently managed to produce a nice factoid question-answering system. In principle, deep semantic analysis of web text could be useful for search (and shallow NLP, like morphology and chunking, perhaps more so); but as the primary thing for a search startup to focus on, it seemed a little extreme.
As to what the “core innovation” was, that’s a loaded question. Was all this stuff useful? Usually I am cynical and say Powerset had no serious innovation for search. But that is just an opinion. Powerset developed some other things that were more user-visible, including a browser of the extracted semantic relations (“Factz” or “Powermouse”), a mostly separate freebase-specific query system (somewhat similar to Google’s recently released Knowledge Graph results), and completely separately, an open-source BigTable clone for index-time infrastructure (HBase, which has been developed quite a bit since then). In general, I found that design/UI engineering people respected Powerset for the frontends, scalability engineers respected Powerset for the HBase contributions, but NLP and IR experts were highly cynical about Powerset’s technology claims. If you get a chance, try asking researchers who were at ACL 2007 in Prague about Barney Pell’s keynote; I am told a number walked out while it was underway.
For good commentary on the situation at the time, see these Fernando Pereira blog posts from 2007: Powerset in PARC Deal, and Powerset in the NYT.
After the acquisition, Microsoft filed patent applications for all the Powerset-specific proprietary tech. You can read all of them on the USPTO website or wherever; for example, this page seems to list them.
Pingback: Automated Text Response Services in Low-Resource Languages « ICT4D @ Tulane